Noobs guide to Flux LoRA training
The Flux model by Black Forest Labs is a state-of-the-art AI model designed to excel in text-to-image generation, standing out for its exceptional image fidelity, prompt adherence, and overall quality. It comes in multiple versions, bigger model Flux.1 Dev and a smaller Flux.1 Schnell. Later is designed for fast, low-step-count generations similar to SDXL Lightning models. These versions make Flux accessible to a wide range of users, from those seeking high-quality imagery to those needing efficient generation on less powerful systems. The models are under non-commercial license, however the image generated through these models can be used commercially.
Flux LoRA is an extension of the Flux model that allows for fine-tuning of the model on custom data. Flux LoRA are much easier to train than their counterparts. This makes Flux LoRA an excellent choice for creators who want to experiment with or specialize in certain visual themes or artistic effects while leveraging the robust capabilities of the Flux model.

In this blog, I will teach you to create your own LoRA in 3 simple steps. Note, services used in this tutorial are not free.
Basics
Dataset Selection: Choose 5–20 clear, high-quality images that best represent you or your product. Ensure they capture key features you want to highlight. Aspect ratio of the image doesn’t matter, but make sure they are at least 1024px resolution.
Captioning the Images: Describe each image in detail, using specific, uncommon words that uniquely define the subject’s key attributes. More on this latter.
Training the Model: Several services can be used for training, such as Replicate, FAL, TheFluxTrain, or Civitai. For this guide, we will use TheFluxTrain due to its user-friendly interface and the ability to input custom captions directly during the training process. First, I’ll show you image that I generated using the finetuned Flux LoRA.





Here are some images that I used for training. Notice the variety in the background. This is very important for AI to understand how to blend your photos in a variety of background. And it also helps to understand the attributes specific to you.



Captioning the Images
Once you have the image, you should caption it. The caption has to very descriptive. It must describe the background and attributes that are not specific to you in details. For example, shades, cloths, bags, etc. During experimentation, I found it useful to describe environment like wind, etc as they interact directly with you image and affect you hairstyles and looks.
TheFluxTrain has an option to autocaption the image during the training, and works fine. But adding your own custom caption produces much better results.
However, writing a good, detailed description that aligns with the model’s representation of the world is very challenging. Thankfully, you don’t have to start from scratch. The platform has feature to generate caption using AI, which you can improve.
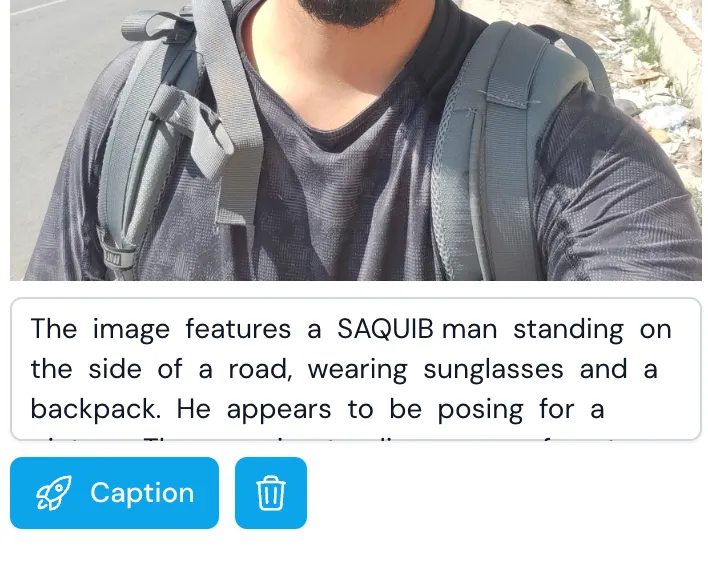
In LoRA, we have a concept of trigger word. This trigger word is intended to capture the details of your image. In the above example, SAQUIB is the trigger word. It has to be something abstract or uncommon. Also, adding the gender after the trigger word helps a lot. Add this keyword wherever required in the sentence. You should also clean the caption as it may contain some details which has very little significance.
After we caption all the images, its time to hit the TRAIN button. On clicking this button, we will be presented with some options. Use the below setting. For person training, usually around 1200 steps is fine. You may need more steps for products with lots of details.
I tried with many LoRA ranks, 32 works best. Lower than this fails to capture enough details, and higher value overfitts real quick.
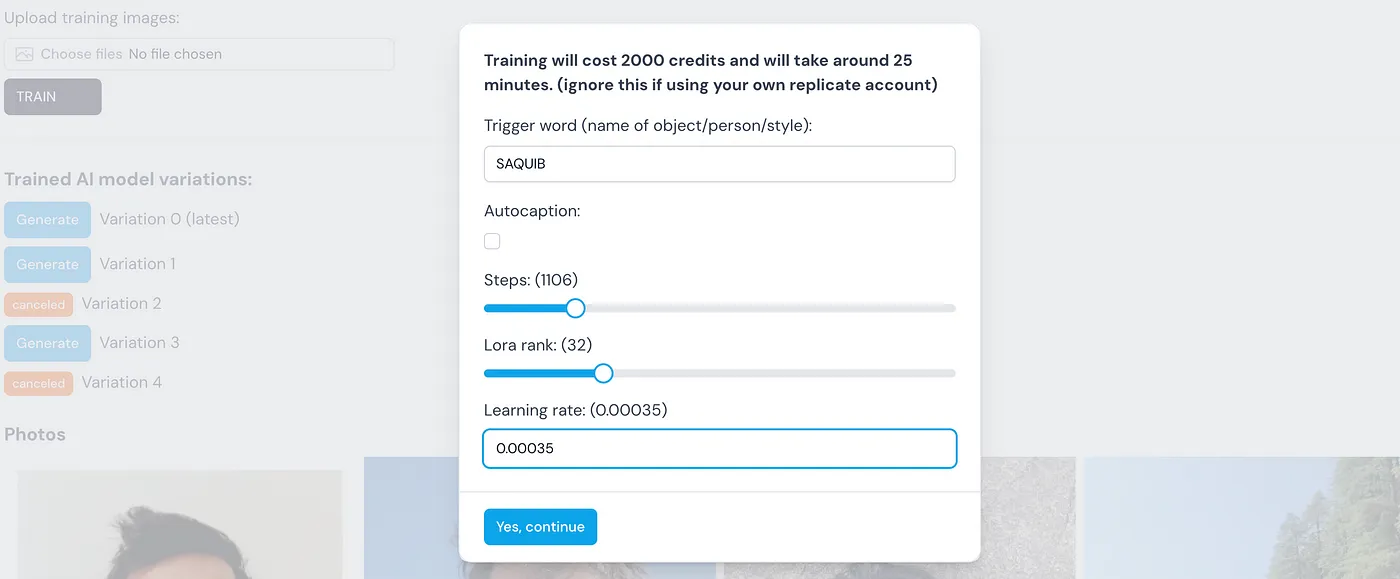
It took around 20 minutes to train this lora and costs around 2000 credits ($4).
Inference
Once your model is trained, it will be visible under the Trained AI model variation list. Click on generate.
In the generate page, you can select bigger model Flux.1 Dev and a smaller Flux.1 Schnell to use with your LoRA. I found Flux.1Dev give much better results. Use maximum steps, 50.
In the prompt field, DO NOT forget to use the trigger word and the gender.
Example-
a photo of SAQUIB man, on new york city wearing old fashion
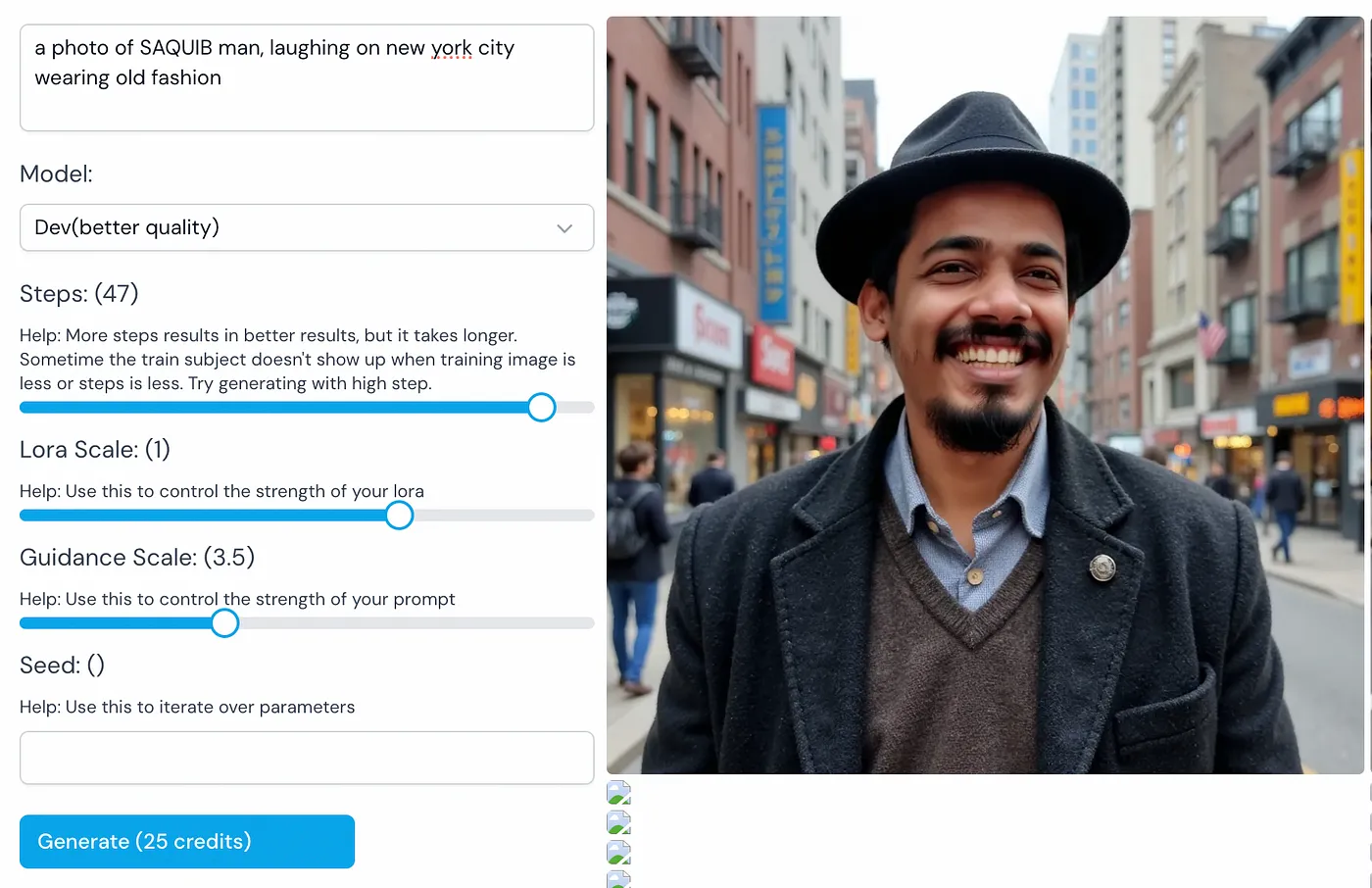
Thats all, enjoy. Put any doubts in the comment and I’ll try my best to answer them. Don’t be afraid to go technical on this.
Cheers!